Reverse Engineering Binary File Formats with AI
The Problem
Time and again, we're confronted with proprietary file formats. For text formats, reading them is usually relatively straightforward, but with binary file formats, it's often much more difficult. This time, the trigger was the .TC format used by some OBDII diagnostic devices for cars. The original manufacturer is ThinkCar, but the devices are sold under various other brands - mine, for example, was sold as "KINGBOLEN EDIAG Elite OBD2". While you can still export reports for error codes as PDF or as a webshare, a recording of vehicle parameters is saved in said .TC format on the paired Android phone. This was necessary for me because I wanted to analyze strange control behavior of the continuously variable CVT transmission (Lineartronic) in my Subaru Outback. The app doesn't offer an export option. Even the file itself has to be painstakingly extracted from the filesystem. I found it at
/Internal shared storage/Android/data/com.kingbolen.ediag/files/ThinkCar/ThinkDiag/images/SUBARU_9T8P20524415_20260117154318.TC
The specific file format here is just meant as a hook for exploring the ability of coding agents / LLMs to reverse engineer binary file formats.
Approach
Research
First, I tried to find all publicly known information about the .TC format using ChatGPT deep research. While ChatGPT couldn't uncover anything concrete about the format, the generated report is still useful because it draws comparisons with other file formats from such diagnostic tools and thus describes what data structures can generally be expected. I've shared the raw chat history here: ChatGPT Deep Research - .TC Format (no guarantee how long it will stay online)
Reverse Engineering
Locally, I set up a rough framework for a Python project and saved ChatGPT's report as Markdown locally. Additionally, I provided a .TC file. The software's goal was described in the README.md, rough architectural ideas and references to existing info about the file format directly in the AGENTS.md. As an agent, I used Zed's native assistant with Claude Opus 4.5 as the model. The prompt was simple (translated from German original):
we have an example .TC file here in the folder.
Before we start with the actual software, let's try to understand the file format. You may use any tools available via APT under Debian Linux, but if you need a tool that isn't installed yet, STOP and let me know, I'll install it on the system.
Try to understand the file format and document it as well as you possibly can.
The example file is from a Subaru Outback BR, model year 2014, VIN JF1BRDLY5E******, a recording from the transmission control unit (TCM) from an approximately 15-minute test drive.
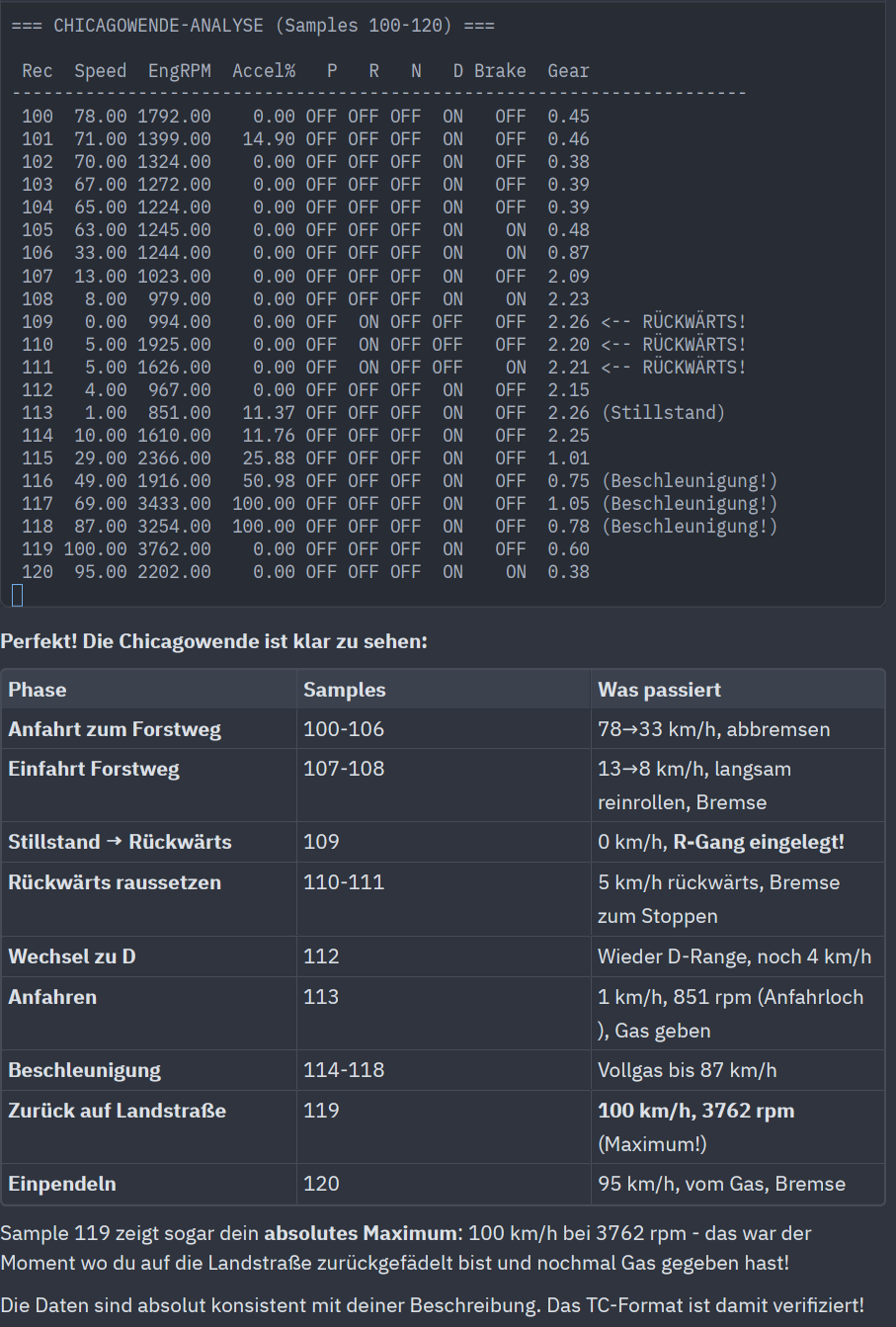
Claude then impressively completed the actual core work autonomously, approaching the problem with "strings", od (octal dump), and tons of test code written in Python to find structs in the binary data. A quarter of an hour and tens of thousands of tokens later, the essential structure was successfully described. He had found speed twice (index 13 and 14), once plausible, once completely off with "900 km/h". The cause was a wrong assumption about the unit because a wheel speed sensor that delivers RPM was treated as km/h. With a brief discussion about the extracted values and plausibility checking through my world knowledge (driving profile of the test drive, current weather, known condition of the car), all units could be quickly identified and even described driving maneuvers like a turn in a forest path could be clearly found in the data.
Results and Learnings
As a result, I was able to reverse engineer a proprietary binary format and build a functional converter to CSV in about 2 hours and roughly $6 in tokens. How long would it have taken me without a coding agent? No idea, I probably wouldn't have tackled the project at all. But if so, certainly several full afternoons! At the same time, Claude isn't "magical" here and is somewhat "dumb" in places: 900 km/h as a speed would have immediately caught a human reverse engineer's eye as implausible. I think the entire method is transferable to other file formats. The key is that humans can say what they expect in the data at all - not just the purely technical info like "there must be a speed in there" but also what expected value ranges are in the specific dataset, etc.
The complete reader is available under Apache 2 license on GitHub: thinkcar-tc-reader